


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
小野寺 直幸; 井戸村 泰宏
Lecture Notes in Computer Science 10776, p.128 - 145, 2018/00
被引用回数:10 パーセンタイル:85.87(Computer Science, Artificial Intelligence)本研究では、局所細分化格子を適用した格子ボルツマン法を開発した。計算コードは、東京工業大学のGPUベースのスーパーコンピュータTSUBAME3.0を用いて開発を行い、最新のPascalアーキテクチャに対して最適化を行なった。1から36ノードを用いた弱スケーリングの性能測定では、NVIDIA TESLA P100を用いたGPU計算がBroadwellによるCPU計算の10倍以上の高速化が達成された。
下川辺 隆史*; 遠藤 敏夫*; 小野寺 直幸; 青木 尊之*
Proceedings of 2017 IEEE International Conference on Cluster Computing (IEEE Cluster 2017) (Internet), p.525 - 529, 2017/09
ステンシルに基づくCFDコードは、規則的なメモリアクセスを持つため、GPUで高い性能を得ることができる。しかしながら、GPUはCPUと比較して、メモリ容量が小さいため、CPUと同様の大きさの問題を解くことができない。そこで、本研究では、CPUのホストメモリとCPUのデバイスメモリの局所性を向上させることが可能な、テンポラルブロッキング法を用いることで、GPUのメモリ容量を超える大きさの計算を可能とした。本研究で開発したフレームワークでは、複雑なコーディングは必要とせずに、テンポラルブロッキング法を含む並列計算用のコードを生成できる。フレームワークを用いて開発した気流解析コードでは、TSUBAME2.5において、GPUのメモリ容量の2倍の計算規模においても、通常のメモリ容量の計算の80%程度の実効性能を達成した。
松本 和也; 朝比 祐一*; 伊奈 拓也; 井戸村 泰宏
no journal, ,
核融合プラズマ流体解析コードGT5Dの主要計算カーネルをGPUクラスタにおいて実装し、性能評価を行った結果を述べる。本研究ではコード内で性能ボトルネックとなっている反復法行列ソルバに対してGPU上でのチューニングを行い、実測性能とルーフラインモデルにより算出した達成可能な実効性能との比較をする。また、複数GPUを使用するためにGPU間直接通信技術を用いた実装についても述べる。
小野寺 直幸; 井戸村 泰宏
no journal, ,
汚染物質の拡散予測シミュレーションは社会的関心が非常に高く、迅速性および正確性が求められている。本研究では、格子ボルツマン法(LBM)に基づいた解析手法を構築することで、実時間拡散解析の実現を目指す。本発表では適合格子細分化法(AMR)法を適用したLBMでの最適なデータ構造および計算アルゴリズムを提案する。
小野寺 直幸; 井戸村 泰宏
no journal, ,
原子力安全保障の観点から、放射性物質の環境動態のリアルタイムシミュレーションが非常に重要である。本研究ではAMR法を用いた格子ボルツマン法に基づくCFDコードを開発した。計算コードは、最新のPascal GPUアーキテクチャで高性能を達成するように最適化されるとともに、テンポラルブロッキング法を導入することによって、MPI通信の通信量の削減に成功した。
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*; 山下 晋; 小野寺 直幸
no journal, ,
多相多成分熱流動解析コードJUPITERの前処理付き共役勾配法(PCG法)向けに混合精度前処理を開発した。この前処理はFP16データとFP32演算を組み合わせたハイブリッドな混合精度演算を採用している。FP16でメモリ上に保存したデータをキャッシュ上でFP32に変換して中間結果をFP32で演算して最終結果をFP16に変換してメモリに戻すことで丸め誤差を低減する。開発した前処理を3,200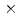 2,00014,160の3次元構造格子を用いた大規模問題で性能測定を実施した。その結果、悪条件行列にFP16データ形式を用いてもPCG法の収束性を維持しつつ、メモリアクセスを削減することでスーパーコンピュータ富岳の2000ノードでFP64前処理実装から1.79倍の高速化を達成した。
2,00014,160の3次元構造格子を用いた大規模問題で性能測定を実施した。その結果、悪条件行列にFP16データ形式を用いてもPCG法の収束性を維持しつつ、メモリアクセスを削減することでスーパーコンピュータ富岳の2000ノードでFP64前処理実装から1.79倍の高速化を達成した。
